- シーンから探す
-
贈る相手から探す
- 彼氏
- 彼女
- 男友達
- 女友達
- 夫・旦那
- 妻・奥さん
- お父さん・父
- お母さん・母
- 両親
- おじいちゃん・祖父
- おばあちゃん・祖母
- 女性
- 男性・メンズ
- 妊婦
- 同僚
- 同僚(男)
- 同僚(女)
- 上司(男)
- 上司(女)
- 部下
- ビジネスパートナー・取引先
- 夫婦
- カップル
- 親友
- 女の子
- 子供
- 男の子
- 赤ちゃん・ベビー
- 乳幼児
- 1歳の誕生日プレゼント
- 2歳の誕生日プレゼント
- 3歳の誕生日プレゼント
- 4歳の誕生日プレゼント
- 5歳の誕生日プレゼント
- 6歳の誕生日プレゼント
- 7歳の誕生日プレゼント
- 8歳の誕生日プレゼント
- 9歳の誕生日プレゼント
- 10歳の誕生日プレゼント
- 18歳の誕生日プレゼント
- 19歳の誕生日プレゼント
- 20歳の誕生日プレゼント
- 21歳の誕生日プレゼント
- 22歳の誕生日プレゼント
- 25歳の誕生日プレゼント
- 26歳の誕生日プレゼント
- 30歳の誕生日プレゼント
- 40歳の誕生日プレゼント
- 50歳の誕生日プレゼント
- 60歳の誕生日プレゼント
- 70歳の誕生日プレゼント
- 80歳の誕生日プレゼント
- 88歳の誕生日プレゼント
- 90歳の誕生日プレゼント
-
カテゴリから探す
- 名入れギフト
- 記念品
- 文房具
- 花
- ビューティー
- こだわりグルメ
- ジュース・ドリンク
- お酒
- 絶品スイーツ
- ケーキ
- お菓子
- プリン
- フルーツギフト
- リラックスグッズ
- アロマグッズ
- コスメ
- デパコス
- インテリア
- キッチン・食器
- グラス
- 家電
- ファッション
- アクセサリー
- バッグ・ファッション小物
- ブランド腕時計(メンズ)
- ブランド腕時計(レディース)
- ベビーグッズ
- キッズ・マタニティ
- カタログギフト
- 体験ギフト
- 旅行・チケット
- ダレスグギフト
- ペット・ペットグッズ
- 面白い
- 大人向けのプレゼント
- 贅沢なプレゼント
- その他ギフト
- プレゼント交換
- 絆ギフト券プロジェクト
- リモート接待・5000円以下
- リモート接待・8000円以下
- リモート接待・10000円以下
- リモート接待・10000円以上
- おまとめ注文・法人のお客様
StanとRでベイズ統計モデリング (Wonderful R 2)

-
商品説明・詳細
-
送料・お届け
商品情報
残り 1 点 3670.00円
(37 ポイント還元!)
翌日お届け可(営業日のみ) ※一部地域を除く
お届け日: 05月28日〜指定可 (明日12:00のご注文まで)
-
 ラッピング
ラッピング
対応決済方法
- クレジットカード
-

- コンビニ前払い決済
-

- 代金引換
- 商品到着と引き換えにお支払いいただけます。 (送料を含む合計金額が¥299,000 まで対応可能)
- ペイジー前払い決済(ATM/ネットバンキング)
-
以下の金融機関のATM/ネットバンクからお支払い頂けます
みずほ銀行 、 三菱UFJ銀行 、 三井住友銀行
りそな銀行 、ゆうちょ銀行、各地方銀行 - Amazon Pay(Amazonアカウントでお支払い)
-

人気商品(ギフトモール店)
全てのギフトを見る-
 桑和 7524-00 防寒ブルゾン(ストレッチ.制電) 6Lサイズ ダークG(109) G.G.
桑和 7524-00 防寒ブルゾン(ストレッチ.制電) 6Lサイズ ダークG(109) G.G.
7220.00 円
-
 【雷市場(ポンジャン)商品韓国直送】 comoninoz ダウンジャケット L サイズ です
【雷市場(ポンジャン)商品韓国直送】 comoninoz ダウンジャケット L サイズ です
3900.00 円
-
 ブレンボ ブレーキパッド セラミックパッド リア ランドローバー ディスカバリー(IV) LA5N/3SB 5.0 V8/3.0 V6 2009年12月~ 入数:1セット(左右) P44 019N
ブレンボ ブレーキパッド セラミックパッド リア ランドローバー ディスカバリー(IV) LA5N/3SB 5.0 V8/3.0 V6 2009年12月~ 入数:1セット(左右) P44 019N
14550.00 円
-
 WL06-109 鉄緑会 中3 数学基礎講座I 代数/幾何/問題集 第1/2部 テキスト 通年セット 2016 計4冊 037M0D
WL06-109 鉄緑会 中3 数学基礎講座I 代数/幾何/問題集 第1/2部 テキスト 通年セット 2016 計4冊 037M0D
5650.00 円
-
 205/65R16 nダンロップ エナセーブ EC203 n中古タイヤ サマータイヤ 2本セットn s16230517807
205/65R16 nダンロップ エナセーブ EC203 n中古タイヤ サマータイヤ 2本セットn s16230517807
7020.00 円
-
 ボーリング ネオンサイン 愿望を叶えた NEON SIGN ネオン管 ネオンサイン アートワーク ウォール ビール バー BAR 喫茶 カフェ 照明 店舗装飾 室内装飾 広告用看板.
ボーリング ネオンサイン 愿望を叶えた NEON SIGN ネオン管 ネオンサイン アートワーク ウォール ビール バー BAR 喫茶 カフェ 照明 店舗装飾 室内装飾 広告用看板.
11890.00 円
あなたへのおすすめ商品
あなたへのおすすめ商品をもっと見る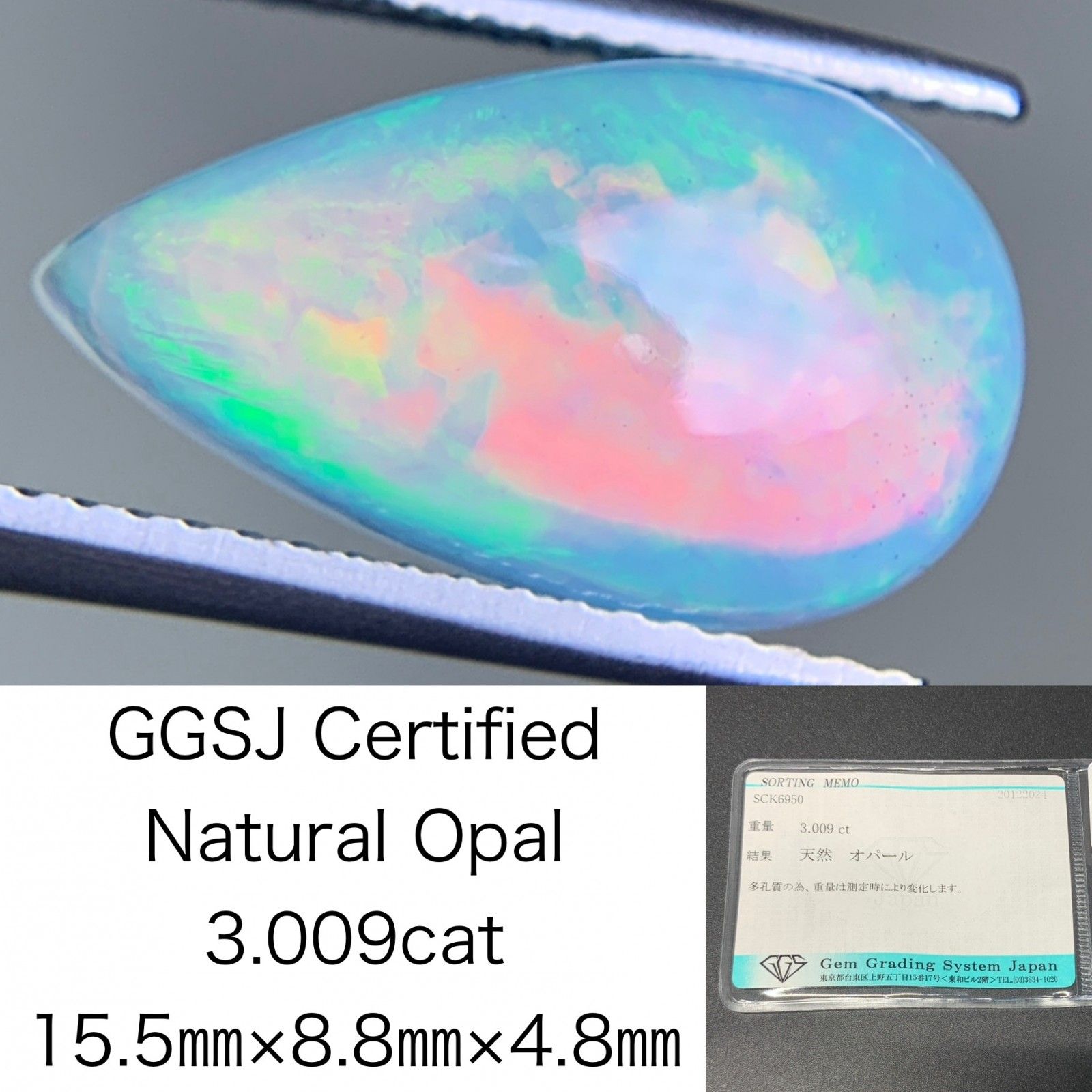
オパール 3.009ct 宝石ソーティング付き 15.5×8.8×4.8 ルース( 裸石 ) 3622Y
4270.00 円

*送料無料* キレイスバル レガシィ 純正 225/45R18 ブリヂストン ポテンザ S007A 18インチ PCD100/5H4020207SYノ
27720.00 円

【中古】アイアンセット エポン AF-Tour CB N.S.PRO MODUS3 TOUR 120 S 27 アイアンセット セット 地クラブ カスタム スチールシャフト おすすめ メンズ 右 [5
38940.00 円

オクヤマ フロアブレース 698 045 0 トヨタ ヴィッツ NCP91
18320.00 円

Life Work(ライフウォーク) 上下セット バックルワッフェン パーカー M + ワイドパンツ S
9630.00 円

ボンネットダンパー ランドローバー ディスカバリー4 L319 2009年~2013年 シルバー ステンレス製 入数:1セット(2個) AP-4T791
9520.00 円

日産/ピットワーク ドライブシャフトブーツ アウター側片側(フロント) AY18R-32014 トヨタ/TOYOTA コロナEXIV/カリーナ ED/セリカ/カレン
3910.00 円
![[新品・未使用]ギフト クリスマス マクラ 低め 高め プレゼント 枕 洗える 快眠枕 横向き寝 誕生日 安眠枕 pilow まくら 首が痛くならない に(60cm*35cm) 低反発 枕 【睡眠の専門家監修x高さ調節](https://assets.mercari-shops-static.com/-/large/plain/j9FaYfJ6rvyDTyNtp4At7j.jpg@jpg)
3610.00 円

4330.00 円

【中古品】 INNOCENCENYC CARDIGAN イノセンスニューヨーク カーディガン グリーン XLサイズ メンズ 【142-250206-st-4-ssa】
11260.00 円




